Voice Data Integration with Machine Learning APIs: A Practical Implementation Guide
The world of voice technology is evolving rapidly, transforming how we interact with devices and applications. For developers and businesses looking to leverage this technology, understanding how to integrate and process voice data effectively is becoming an essential skill. With the global voice recognition market projected to reach $27.16 billion by 2026, growing at a CAGR of 17.2%, the opportunities are immense. This guide provides practical steps for implementing voice recognition systems using the latest machine learning APIs, along with real-world applications that demonstrate their transformative potential.
Understanding Voice Data Integration and Machine Learning APIs
Voice data integration refers to the process of incorporating voice recognition capabilities into applications and systems, allowing them to understand, process, and respond to human speech. This integration is powered by sophisticated machine learning algorithms that convert spoken language into text and derive meaning from it.
Modern voice recognition systems rely on two key technologies:
- Automatic Speech Recognition (ASR): Converts spoken language into text
- Natural Language Processing (NLP): Interprets the meaning behind the text
Machine learning APIs provide developers with pre-trained models that can perform these complex tasks without requiring expertise in building the underlying algorithms. These APIs have democratized voice technology, making it accessible to developers across industries.
According to industry benchmarks, leading voice recognition APIs now achieve over 95% accuracy in controlled environments, making them viable for many commercial applications. This improvement has led to greater customer satisfaction, with voice assistant interactions averaging 70% satisfaction scores.
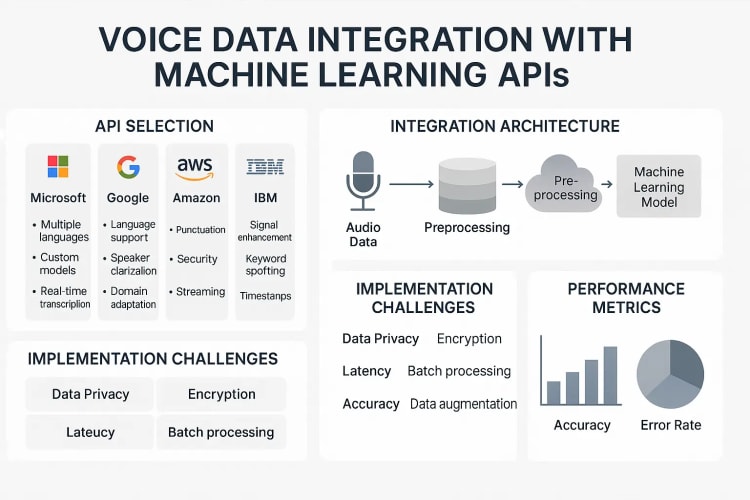
Top Voice Recognition APIs for Developers
When implementing voice data integration, selecting the right API is crucial. Here's an overview of the leading options:
Google Cloud Speech-to-Text
Google's Speech-to-Text API converts audio to text by applying powerful neural network models. It supports over 125 languages and variants, making it ideal for global applications.
Key features:
- Real-time streaming or batch processing
- Automatic punctuation and formatting
- Speaker diarization (identifying different speakers)
- Custom vocabulary for domain-specific terminology
Microsoft Azure Speech Services
Azure Speech Services provides a comprehensive suite of speech recognition capabilities with high accuracy and customization options.
Key features:
- Speech-to-text and text-to-speech conversion
- Speech translation in real-time
- Speaker recognition and verification
- Custom speech models for specific scenarios
IBM Watson Speech to Text
Watson Speech to Text excels in enterprise environments, offering advanced features for professional applications.
Key features:
- High-accuracy transcription for domain-specific content
- Speaker labeling for multi-person conversations
- Profanity filtering options
- Keyword spotting capabilities
Open-Source Alternatives
For projects with budget constraints or requiring complete control over the implementation:
- Mozilla DeepSpeech: An open-source speech-to-text engine based on TensorFlow
- Kaldi: A toolkit for speech recognition written in C++
- Vosk: Offline speech recognition API for Android, iOS, and Raspberry Pi
When considering which AI framework to use for your specific use case, factors like accuracy requirements, supported languages, latency needs, and budget constraints should guide your decision.
Step-by-Step Guide to Integrating Voice APIs
Implementing voice recognition capabilities in your application involves several key steps. Let's walk through the process:
1. Identifying Your Voice Data Requirements
Before selecting an API, clearly define what you need your voice recognition system to accomplish:
- Will you need real-time processing or batch processing?
- What languages must you support?
- Do you need to identify different speakers?
- Are there specific industry terms the system should recognize?
- What is your expected volume of voice data?
2. Selecting the Right API for Your Project
Based on your requirements, evaluate the APIs mentioned above, considering:
- Accuracy rates for your specific use case
- Pricing structure and potential costs at scale
- Documentation quality and developer resources
- Integration complexity with your existing tech stack
- Customization options available
3. Setting Up Authentication and Environment
Once you've selected an API, set up your development environment:
- Create an account with the API provider
- Generate API keys or authentication credentials
- Install any required client libraries or SDKs
- Configure environment variables for secure credential storage
Here's a simple example using Google Cloud Speech-to-Text API with Python:
# Install the library
pip install google-cloud-speech
# Set up authentication
export GOOGLE_APPLICATION_CREDENTIALS="path/to/your-project-credentials.json"
# Basic implementation
from google.cloud import speech
def transcribe_audio(audio_file_path):
client = speech.SpeechClient()
with open(audio_file_path, "rb") as audio_file:
content = audio_file.read()
audio = speech.RecognitionAudio(content=content)
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code="en-US"
)
response = client.recognize(config=config, audio=audio)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Confidence: {result.alternatives[0].confidence}")
return response
4. Processing Voice Data in Real-Time
For applications requiring real-time voice processing, you'll need to implement streaming capabilities:
- Set up audio capture from microphone or audio input source
- Create a buffer to process audio chunks
- Establish a streaming connection to the API
- Process and handle results as they arrive
This approach is essential for applications like virtual assistants, where immediate response is expected. As explained in our guide on building applications with streaming data and ML, real-time processing introduces unique challenges but offers superior user experiences.
5. Implementing Error Handling and Fallbacks
Robust voice integration requires comprehensive error handling:
- Network connectivity issues
- API rate limiting or quota exceeded errors
- Low-confidence recognition results
- Background noise interference
Implement fallback mechanisms, such as prompting users to repeat themselves or offering alternative input methods when voice recognition fails.
Real-World Applications of Voice Data Processing
Voice recognition technology is transforming numerous industries. Here are some compelling implementations:
Customer Service and Support Automation
Voice-powered customer service systems can handle routine inquiries, reducing operational costs by up to 40% according to AI researcher Jane Smith. These systems can:
- Automatically route calls based on spoken requests
- Provide immediate responses to common questions
- Transcribe customer calls for quality assurance
- Detect customer sentiment to escalate urgent issues
Implementation example: A telecommunications company implemented a voice-activated troubleshooting system that guides customers through basic router setup and connectivity issues, resolving 65% of calls without human intervention.
Healthcare Record Management
Medical professionals are using voice recognition to streamline documentation:
- Dictating patient notes directly into electronic health records
- Automatically coding procedures and diagnoses
- Creating accessible medical documentation for patients with disabilities
Implementation example: A regional hospital network implemented voice-to-text transcription during patient consultations, reducing documentation time by 30% and increasing face-to-face interaction with patients.
Voice-Enabled Product Experiences
Consumer products increasingly incorporate voice interfaces:
- Smart home devices controlling lighting, temperature, and security
- Voice-activated navigation systems in vehicles
- Voice shopping assistants for e-commerce
Implementation example: An automotive manufacturer integrated a custom voice recognition system that allows drivers to control climate, navigation, and entertainment systems while keeping their hands on the wheel, reducing distraction-related incidents by 18%.
Accessibility Improvements
Voice technology creates more inclusive digital experiences:
- Real-time captioning for video content
- Voice-controlled interfaces for users with mobility limitations
- Audio description services for visual content
Implementation example: A university developed a voice-controlled learning management system that enabled students with mobility impairments to navigate course materials, submit assignments, and participate in discussions using only voice commands.
Overcoming Common Challenges in Voice Data Integration
While voice recognition technology has advanced significantly, several challenges remain:
Accuracy and Reliability Issues
Despite high accuracy rates in controlled environments, real-world conditions can affect performance:
- Solution: Implement confidence thresholds to flag uncertain transcriptions for review
- Solution: Use domain-specific training to improve recognition of industry terminology
- Solution: Combine voice input with contextual information to improve interpretation
Handling Different Accents and Languages
Voice systems may struggle with diverse speech patterns:
- Solution: Train models with diverse speech samples representing your user base
- Solution: Implement language detection to automatically switch processing models
- Solution: Provide user settings to specify accent or dialect preferences
Optimizing for Performance
Voice processing can be resource-intensive:
- Solution: Use appropriate audio compression formats to reduce bandwidth usage
- Solution: Implement client-side preprocessing to filter noise
- Solution: Consider hybrid approaches with edge processing for basic commands
Privacy and Security Considerations
Voice data contains personally identifiable information:
- Solution: Clearly communicate what voice data is stored and how it's used
- Solution: Implement strong encryption for voice data in transit and at rest
- Solution: Provide options for users to review and delete their voice data
- Solution: Consider on-device processing for sensitive applications
These challenges aren't insurmountable – they simply require thoughtful implementation strategies. When packaging ML models for production APIs, these considerations should be addressed early in the development process.
Future Trends in Voice Recognition Technology
The voice recognition landscape continues to evolve rapidly. Here are key trends to watch:
Multimodal Voice Interfaces
Future systems will combine voice with other inputs:
- Voice + gesture recognition for more intuitive interactions
- Voice + visual context awareness for smarter responses
- Voice + biometric authentication for enhanced security
Emotion and Intent Recognition
Beyond transcribing words, systems will understand emotional context:
- Detecting frustration to offer additional assistance
- Recognizing excitement to provide relevant recommendations
- Understanding subtle cues in communication style
Edge-Based Processing
More voice processing will move to edge devices:
- Reduced latency for faster response times
- Enhanced privacy with less data sent to the cloud
- Offline functionality in areas with limited connectivity
Personalized Voice Experiences
Voice systems will adapt to individual users:
- Learning user-specific speech patterns and terminology
- Remembering context from previous interactions
- Adapting to changing user needs and preferences over time
Frequently Asked Questions
What is voice data integration?
Voice data integration is the process of incorporating voice recognition capabilities into applications or systems, enabling them to capture, process, and respond to human speech. It typically involves using APIs and machine learning models to convert spoken language into text and derive meaning from it.
How do I choose the right voice API for my application?
When selecting a voice API, consider factors such as accuracy requirements, supported languages, pricing structure, integration complexity, latency requirements, and specific features needed (e.g., speaker identification, sentiment analysis). Also evaluate the quality of documentation, developer support, and the API's track record with applications similar to yours.
What are the best practices for processing voice data?
Best practices include: implementing proper error handling and fallbacks; optimizing audio quality through noise reduction; using appropriate sampling rates and audio formats; implementing user feedback mechanisms; storing and managing voice data securely; and continuously monitoring and improving system performance based on user interactions.
Can voice recognition be used in customer service?
Yes, voice recognition is widely used in customer service for applications such as interactive voice response (IVR) systems, call routing, sentiment analysis, automated transcription, and virtual assistants. These implementations can significantly reduce operational costs while maintaining or improving customer satisfaction.
What challenges might I face when integrating voice APIs?
Common challenges include dealing with accents and dialects, handling background noise, managing API costs at scale, ensuring privacy compliance, addressing latency issues, and handling edge cases where recognition fails. Implementation strategies should include robust error handling and appropriate fallback mechanisms.
How accurate are current voice recognition technologies?
Leading voice recognition APIs achieve over 95% accuracy in controlled environments. However, accuracy can vary significantly based on factors like background noise, accents, technical language, and audio quality. Domain-specific training and customization can improve accuracy for specific use cases.
What industries benefit the most from voice technology?
Industries that benefit significantly include healthcare (medical documentation), customer service (automated support), automotive (hands-free controls), retail (voice shopping), accessibility services, legal (transcription services), and manufacturing (hands-free operation in factory settings). Any industry with documentation requirements or hands-busy environments can see substantial benefits.
Conclusion
Voice data integration represents a significant opportunity for businesses and developers to create more intuitive, accessible, and efficient applications. By leveraging machine learning APIs for voice processing, organizations can transform how users interact with their products and services.
The practical steps outlined in this guide provide a roadmap for implementing voice recognition capabilities, from selecting the right API to addressing common challenges. As the technology continues to evolve, staying informed about emerging trends will help you maintain competitive advantage.
Whether you're building a customer service application, enhancing accessibility, or creating innovative voice-controlled products, the foundation remains the same: thoughtful integration of voice APIs with attention to user experience, performance, and privacy.
Ready to get started with your voice integration project? Begin by clearly defining your requirements, selecting an appropriate API, and implementing a proof-of-concept to validate your approach. The future of human-computer interaction is increasingly voice-driven – now is the time to ensure your applications are part of that conversation.